Google Speech APIの利用する環境としては、Google Cloud SDKをインストールすることで自身のPC(Linux, Windows, Mac)を利用することも可能ですが、Google Cloud Platform(GCP) APIへのアクセス環境が設定済みのGoogle Cloud Shell(UnixのShell環境)を利用するのが一番手っ取り早いようです。また、利用にはプログラミング言語を使う必要がありますので、本稿ではPythonを利用した例を説明しますがプログラミングの知識は必要ありません。他にも、C#, Go, Java, Node.JS, PHP, Rubyに対応しているようです。
そのため、本稿ではGoogle Cloud Shellを利用したGoogle Speech APIの利用方法を説明します。
参考ページこちら。
Cloud APIの認証設定
Google Speech APIへアクセスするためには認証が必要です。次に認証設定をしていきます。
- GCP ConsoleのAPIとサービス -> 認証情報からサービス アカウント キーを選択します。
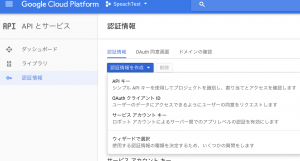
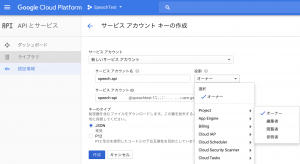
- 新しいサービスアカウントを選択します。サービスアカウント名に任意の名前を入力し、役割には「Projecrt」-> 「オーナー」を選びます。
- キーのタイプはJSONとし作成を実行します。そうするとJSON形式のアクセスキーのファイルがダウンロードされますのでローカルのパソコンにまずは保存してください。
- 次にキーファイルをGoogle Cloud Shellへアップロードします。まずは、GCP Consoleの右上のShellアイコン(画面例の黄色の下線参照)をクリックしてGoogle Cloud Shellを実行します。
![]()
- そこから先ほどのJSONファイルをアップロードします。Shellの右上のメニューからファイルのアップロードを選択し、ファイルをShellへアップロードして下さい。
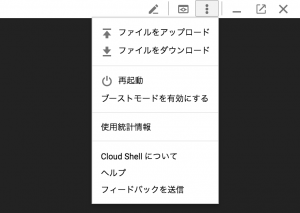
- アップロードしたら以下のシェルコマンドを実行し、Google Cloud Shellへ認証情報を設定します。
% export GOOGLE_APPLICATION_CREDENTIALS="ファイル名"
これでAPIを呼び出す準備は完了です。お疲れ様でした。
次回は実際に Pythonプログラムから音源ファイルをSpeech APIを使ってテキスト化を行います。