ここまで準備ができたら早速録音した音源のテキスト化を行います。Googleの説明によると音源はロスレスのFLAC or LINEAR1が推奨されています。その他、圧縮音源を使わざる得ない場合は、AMR_WB, OGG_OPUS , SPEEX_WITH_HEADER_BYTE(推奨の順番順)がサポートされています。iPhoneなどアップル製品のデフォルトのm4a音源はサポートされていません。従って、m4aのような圧縮音源をテキスト化したい場合は、これらのサポート音源に変換する必要があります。
Speech API実行プログラムの作成
では、Google Speechのページのサンプル(Python)を利用して音源のテキスト化を行います。Google Cloud Shellの画面から任意のエディタ(vi, emacs等)を使ってリンクのtranscribe_async.pyをコピーしてGoogle Cloud Shell内に保存します。保存場所はどこでも構いません。
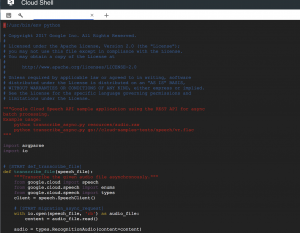
なお、プログラム内のlanguage_code=’en-US’を日本語の場合はlanguage_code=’ja-JP’に変更します。
音源をGoogle Cloud Strageに保存する
次に音源を保存します。Google Speech APIの説明によれば音源はファイルを直接APIで送る(1分以内の小さいファイルの場合)かGoogle Cloud Storageから読み取るの二択のようです。 そのため、音源ファイルをGoogle Cloud Strageに保存します。
まず、Google Cloud Strageのバケットを作成します。(最初の場合)
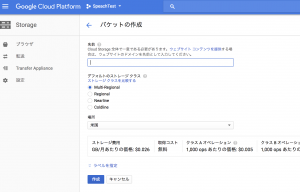
以下のように任意のバケット名を設定し作成してください。
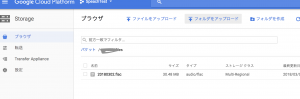
以下の画面例のように、バケットへ音源ファイルをアップトードできたらOKです。
バケットへのURIは以下のようになります。
gs://(バケット名)/(ファイル名)
Pythonスクリプトの実行
これで全ての準備が終わりましたので、早速、Google Speech APIを叩いてみます。Google Cloud Shellから以下のように先ほどのスプリプトを実行します。(ちなみに、brooklyn.flacは公開ファイルなのでどなたでもそのまま実行できます。)
% python transcribe_async.py gs://cloud-samples-tests/speech/brooklyn.flac
以下のような結果が帰ってきたら成功です!
Waiting for operation to complete... Transcript: how old is the Brooklyn Bridge Confidence: 0.984530925751
結果をファイルに保存したい場合は
% python transcribe_async.py gs://cloud-samples-tests/speech/brooklyn.flac > (ファイル名)
のようにファイル名を指定してリダイレクトすればOKです。
音源ファイルの変換
音源ファイルの変換はhttps://audio.online-convert.com/convert-to-flacが便利です。